
こんにちは。
駆け出しエンジニアの:DaVです。
つい先日ほぼ皆既の部分月食が確認されたそうですね!
私は室内にいたので観測できなかったのですが、皆さんはいかがでしたでしょうか?
最近月がとても綺麗なので上を見ながら歩きたくなりますよね:)
あ、告白じゃないですよ。
それはさておき、今回はPython勉強の一環として、ライブラリを利用してPowerPointからイメージマップを生成するスクリプト開発に挑戦しましたので、記事に残したいと思います:D
Pythonを用いてPowerPointの自動化や連携を考えている方の参考になれば幸いです:)
読むのが面倒な方はGitHubにも公開していますので、そちらをご覧ください!
もしくは目次から「実行結果」まで読み飛ばしてください。
それでは、早速!
今回のゴール
PythonのPowerPoint用ライブラリを使用し、ハイパーリンクを埋め込んだPowerPointをスライドごとにイメージマップ化することが今回のゴールです:D
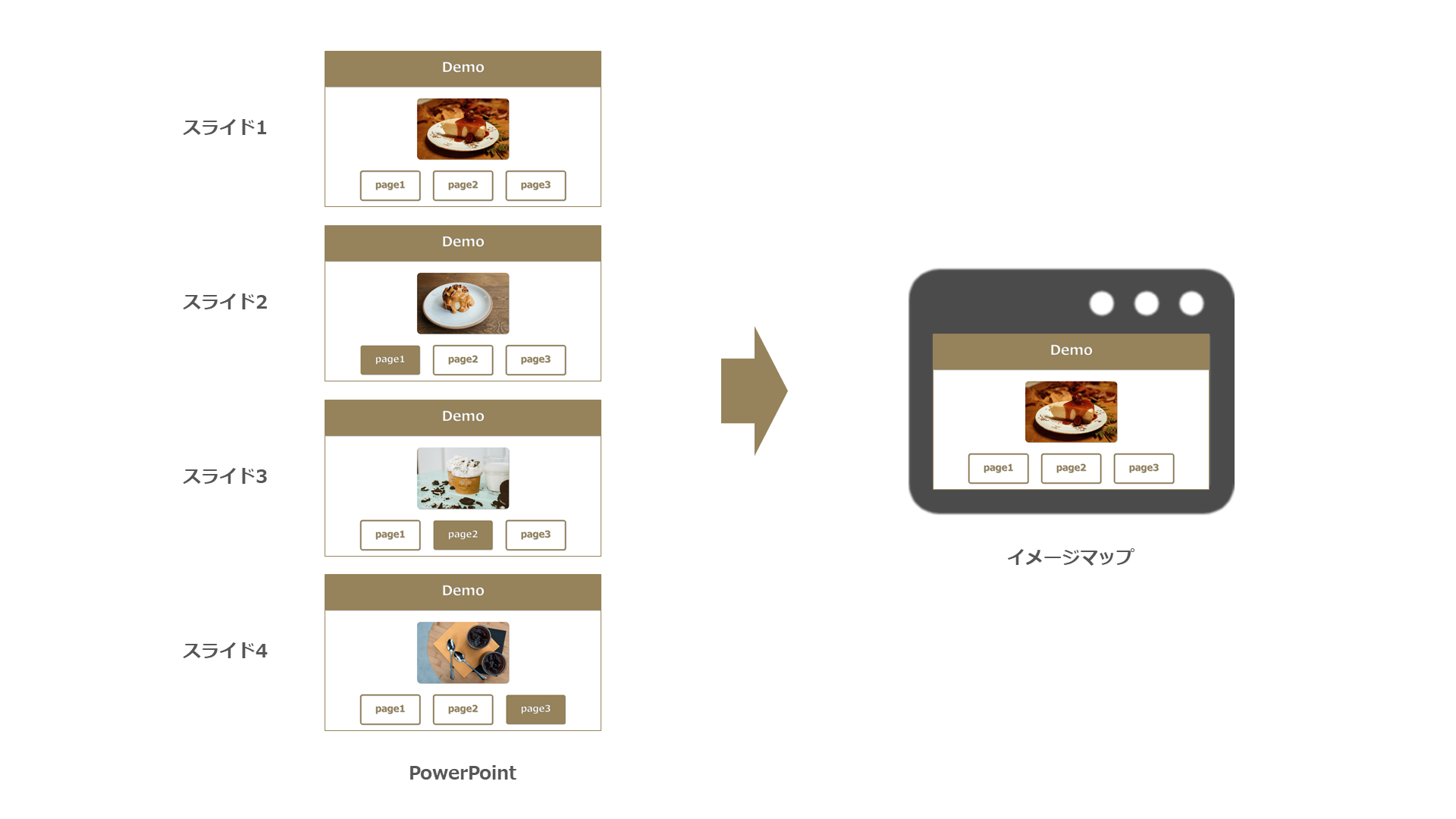
パワポ側でワイヤーフレーム的なものを作成した際に便利になるかと思い試してみました。
PowerPoint用ライブラリ「python-pptx」
「python-pptx」は、PowerPointを作成したり更新したりできるライブラリです。
テキストを抽出したり、テンプレートの自動作成するときとかに便利みたいですね:D
ちなみにこのライブラリはプレゼンテーション(.pptx)形式のみ対応しているため、スライドショー(.ppsx)形式に対してのアクセスは出来ないみたいです。
また、スライドマスターやグループ化されたオブジェクトの子要素に対する複雑な操作もできないみたいなので、要注意です。
まぁシンプルな操作はできるので全然問題ないと思いました:)
公式のドキュメントはコチラです。
ということで今回はこの「python-pptx」ライブラリを使用してパワポからイメージマップの自動生成を目指します!
イメージマップとは?
イメージマップはWebサイトに配置した画像に対して、任意の座標にリンクをつける実装方法です。
通常だとAdobeのPhotoshopやBracketsを利用したり、オンラインのジェネレータサービスを利用して座標を取るのですが、これをパワポからでもできないかなぁ~と思い挑戦してみました:)
Webのワイヤーフレームやモックアップを作成する際、PowerPointを使用することもあるかもしれませんので活用できればって感じのノリです。
あ、車輪の再発明は禁句ですよ!
環境準備
というわけで準備編です。
下記環境で諸々をインストールしていきます!
- Windows10 Home 64bit
- Visual Studio Code 1.62.1
- Python 3.9.6
python-pptxをインストール
pipで一発です:D
pip install python-pptx画像処理ライブラリをインストール
画像のサイズ情報を取得するためにPillowライブラリをインストールします。
pip install pillowjQuery をダウンロード
後述のプラグインを利用するため、ローカルで実行したい人はコチラからダウンロードしておきましょう。
CDNの場合は不要ですね:D
RWD Image Maps をダウンロード
イメージマップをレスポンシブに対応させるために「RWD Image Maps」を使用します。
コチラから「jquery.rwdImageMaps.min.js」をダウンロードします。
PowerPointの準備
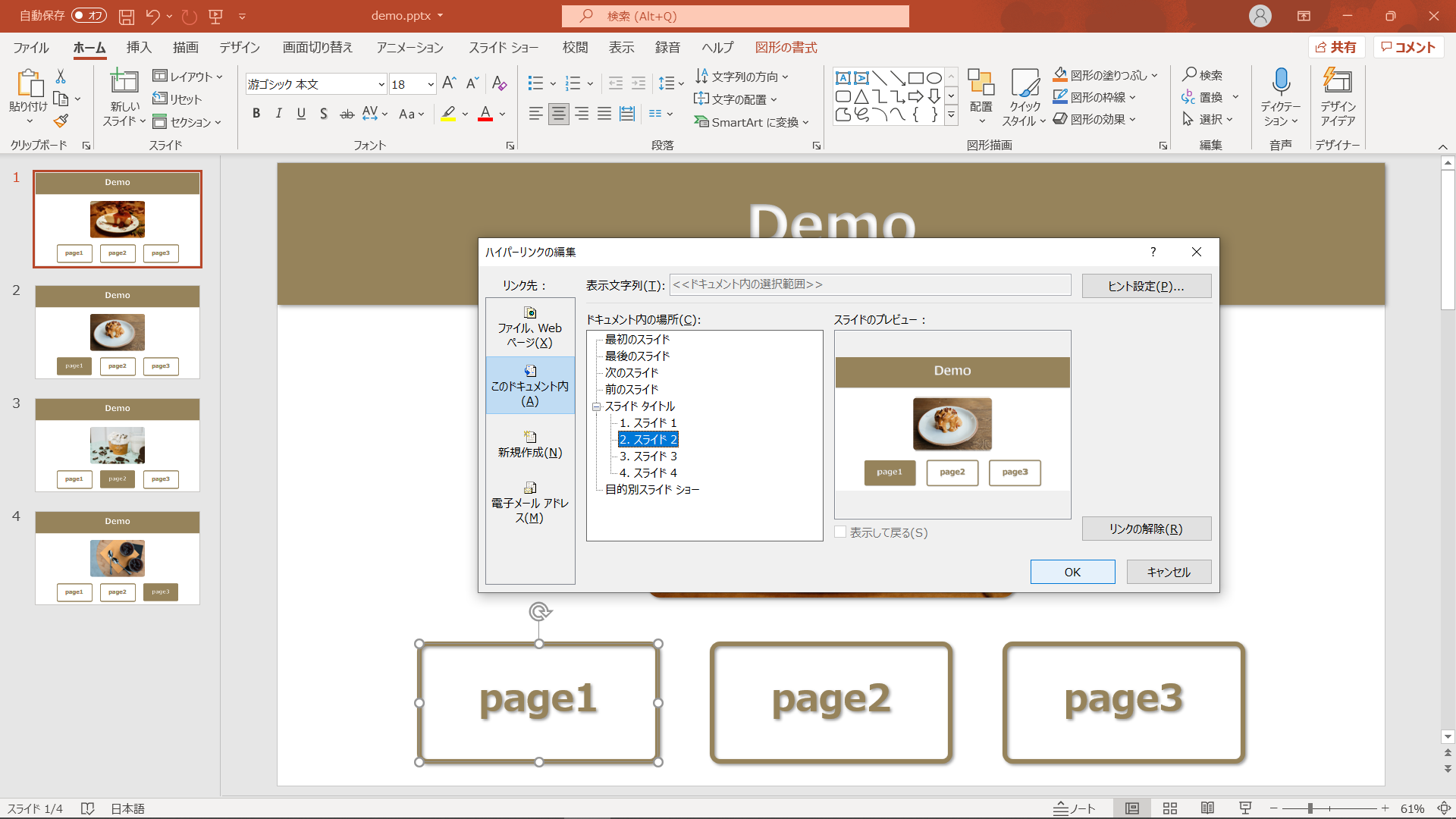
ハイパーリンク付きのプレゼンテーションファイル作成します。
スライド間のリンクがあればとりあえずなんでもOKです。
ただし、先述したようにグループ化されたオブジェクトの子要素にはアクセスできないため、あくまで個別にハイパーリンクを付与するのがポイントです。
こんな感じで貼っていきます↓
とりあえず試してみたい方は以下からご自由にダウンロードしてください:D
ちなみに今回はイメージマップのサイズを「1920*1080px」にしたかったので、PowerPointのサイズを「50.8cm*28.575cm」(1920*1080px)に設定してます:D
コード実装
諸々の準備が整ったら早速実装していきます:D
HTML/CSSテンプレートの作成
まずはこんな感じのイメージマップ用のテンプレートを用意しておきます。
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<title>{% title %}</title>
<link rel="stylesheet" href={% csspath %}>
<script type="text/javascript" src={% jqpath %}></script>
<script type="text/javascript" src={% rwdpath %}></script>
</head>
<body>
<div class="container">
<img src={% imgpath %} width={% imgwidth %} height={% imgheight %} usemap="#image-map">
<map name="image-map">
{% maparea %}
</map>
</div>
<script>
$(document).ready(function () {
$('img[usemap]').rwdImageMaps();
});
</script>
</body>
</html>
{%%}で区切っている部分にPowerPointから取得した情報を埋め込む感じです:D
scriptには「RWD Image Maps」用の処理を記述し、レスポンシブ対応します。
このHTMLファイルがPowerPointのスライド枚数分出力される感じです。
CSSは適当ですがこんな感じです。
::-webkit-scrollbar {
display: none;
-webkit-appearance: none;
}
html,body {
margin: 0px;
height: 100%;
background-color:#10100E;
}
.container {
height: 100%;
display: flex;
}
img{
height: auto;
max-height:100%;
width: auto;
max-width: 100%;
margin: auto;
}今回のキモはPythonからPowerPointへのアクセスすることなので、こんなもんです:(
PythonでPowerPointからHTMLへの変換処理を実装
ちょっと長いのでポイントだけ解説します。
python-pptxのインポート
基本の「Presentation」のほか、リンクやグループオブジェクトを判定するため、「PP_ACTION」と「MSO_SHAPE_TYPE」のモジュールもインポートします。
from pptx import Presentation
from pptx.enum.action import PP_ACTION
from pptx.enum.shapes import MSO_SHAPE_TYPEPowerPointのプロパティ取得
Presentation()でプロパティを取得します。(ppt_nameには.pptxのパスを渡します。)
dst_ppt = Presentation(ppt_name)emuをピクセルに変換
PowerPointのサイズは「emu」という単位で取得されるため、ピクセルに変換します。
ADJUST = 12700
PT = (1 / 72) * 2.54
PIXEL = 0.0264
def emuToPx(emu):
return int(emu / ADJUST * PT / PIXEL)
ppt_px_width = emuToPx(dst_ppt.slide_width)※dpi=96ドットの場合で計算しています。
グループオブジェクトとハイパーリンクの検出
グループの子要素にアクセスできないため、スライド内のグループ化されていないオブジェクトについて、ハイパーリンクであるかどうかを確認してます。
for i, sld in enumerate(dst_ppt.slides, start=1): # スライドループ
…
for shp in sld.shapes: # シェイプループ
…
if shp.shape_type != MSO_SHAPE_TYPE.GROUP: # グループオブジェクトチェック
click_action = shp.click_action
…
if click_action.action == PP_ACTION.NAMED_SLIDE: # ハイパーリンクチェック
…コード全体
全文を見たい方は下のボタンをクリック、もしくはGitHubをご覧ください:)
# -*- coding: utf-8 -*-
import sys, io, os
import pprint
import codecs
from pptx import Presentation
from pptx.enum.action import PP_ACTION
from pptx.enum.shapes import MSO_SHAPE_TYPE
import glob
import argparse
from PIL import Image
# japanese
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
# Index
HEIGHT = 0
WIDTH = 1
CHANNEL = 2
# Path
SRC_PPT_PATH = "src_ppt.pptx"
image_path = "./image"
# Val
ADJUST = 12700
PT = (1 / 72) * 2.54
PIXEL = 0.0264
DEFAULT_HEIGHT = 1920
DEFAULT_WIDTH = 1080
# find pptx file
def getPptName():
name = ''
for fl in glob.glob('./*.pptx'):
name = os.path.split(fl)[1]
print('Target : ' + name)
return name
def emuToPx(emu):
return int(emu / ADJUST * PT / PIXEL)
def getImgSize():
img_list = glob.glob('image/*.png')
if len(img_list) > 0:
img = Image.open(img_list[0])
else :
return 1920, 1080
return img.width, img.height
def convertMain(args):
x, y = getImgSize()
if args.width != 'default':
x = int(args.width)
if args.height != 'default':
y = int(args.height)
csspath = '"' + str(args.csspath) + '"'
jqpath = '"' + str(args.jqpath) + '"'
rwdpath = '"' + str(args.rwdpath) + '"'
imgwidth = '"' + str(x) + '"'
imgheight = '"' + str(y) + '"'
# main
print('#### Start program! ####')
# Get ppt file name
ppt_name = ''
ppt_name = getPptName()
if ppt_name == '':
print("not found .pptx file")
exit()
print("image width : " + str(x) + "px")
print("image height : " + str(y) + "px")
# Get Ppt Infomation
dst_ppt = Presentation(ppt_name)
ppt_px_width = emuToPx(dst_ppt.slide_width)
# Calc image ratio
ratio = x / ppt_px_width
# ppt_data = {slide_number: slide_data, ....}
ppt_data = {}
# ppt_name_data = {slideID: slide_number, ...}
ppt_name_data = {}
# ppt slide loop
for i, sld in enumerate(dst_ppt.slides, start=1):
# slide_data = {name: '', id: '', link_count: ''}
ppt_slide_data = {}
ppt_data[str(i)] = ppt_slide_data
ppt_slide_data["name"] = 'slide' + str(i)
ppt_slide_data["id"] = str(sld.slide_id)
ppt_name_data[str(sld.slide_id)] = 'slide' + str(i)
ppt_slide_data['link_count'] = 0
# j = link count
j = 0
# shape loop
for shp in sld.shapes:
# print("shp.name : ", shp.name)
# Not Group Shape
if shp.shape_type != MSO_SHAPE_TYPE.GROUP:
click_action = shp.click_action
# check shape type
if click_action.action == PP_ACTION.NAMED_SLIDE:
# print("shp.name : ", shp.name)
ppt_slide_data['link_count'] += 1
shp_px_width = emuToPx(shp.width)
shp_px_height = emuToPx(shp.height)
shp_px_x1 = emuToPx(shp.left)
shp_px_y1 = emuToPx(shp.top)
shp_px_x2 = shp_px_x1 + shp_px_width
shp_px_y2 = shp_px_y1 + shp_px_height
img_px_x1 = int(shp_px_x1 * ratio)
img_px_y1 = int(shp_px_y1 * ratio)
img_px_x2 = int(shp_px_x2 * ratio)
img_px_y2 = int(shp_px_y2 * ratio)
ppt_slide_data['link' + str(j) + '_x1'] = str(img_px_x1)
ppt_slide_data['link' + str(j) + '_y1'] = str(img_px_y1)
ppt_slide_data['link' + str(j) + '_x2'] = str(img_px_x2)
ppt_slide_data['link' + str(j) + '_y2'] = str(img_px_y2)
ppt_slide_data['link' + str(j) + '_target_name'] = 'tmp'
target = click_action.target_slide
# DBG
# print("target : " + str(target.slide_id))
ppt_slide_data['link' + str(j) + '_target_id'] = target.slide_id
j += 1
if j == 0:
print("Warning : Not exist link-object in slide" + str(i) + ".")
# PPT dict loop
print('#### Create slideX.html ####')
for k in ppt_data:
# html page data
page_data = {}
page_data['title'] = ppt_name.replace('.pptx','') + ' ' + ppt_data[k]['name']
page_data['csspath'] = csspath
page_data['jqpath'] = jqpath
page_data['rwdpath'] = rwdpath
page_data['imgpath'] = '"' + 'image/' + 'スライド' + k + '.png' + '"'
page_data['imgwidth'] = imgwidth
page_data['imgheight'] = imgheight
# creat area tag
area_all_str = ''
if ppt_data[k]['link_count'] != 0:
for lc in range(ppt_data[k]['link_count']):
idx = str(lc)
area_str = '<area href="' + ppt_name_data[str(ppt_data[k]['link' + idx + '_target_id'])] + '.html" coords="'
# print("LINK " + str(lc))
area_str = area_str + str(ppt_data[k]['link' + idx + '_x1']) + ',' + str(ppt_data[k]['link' + idx + '_y1']) + ',' \
+ str(ppt_data[k]['link' + idx + '_x2']) + ',' + str(ppt_data[k]['link' + idx + '_y2'])
area_str = area_str + '" shape="rect">' + "\n"
area_all_str = str(area_all_str) + area_str
page_data['maparea'] = area_all_str
# read temlate.html
with open('template/template.html','r') as file:
html = file.read()
file.closed
# replace {% %} to page_data
for key, value in page_data.items():
html = html.replace('{% ' + key + ' %}', value)
# html output
f = codecs.open('slide' + k + '.html', 'w', 'utf-8')
print(html, file=f)
print("#### Complete! ####")
def checkArguments(size):
if size.isdigit():
if int(size) > 0 and int(size) < 10000:
return True
else:
print('Value error...')
return False
elif size == 'default':
return True
else:
print('No other than numbers...')
return False
def getArguments():
parser = argparse.ArgumentParser(description='.pptxの各スライドをクリッカブルマップにコンバートします。')
parser.add_argument('-W', '--width', required=False, default='default' ,help='クリッカブルマップ対象の画像の幅(default:image内のpngサイズ)')
parser.add_argument('-H', '--height', required=False, default='default', help='クリッカブルマップ対象の画像の高さ(default:image内のpngサイズ)')
parser.add_argument('-J', '--jqpath', required=False, default='https://code.jquery.com/jquery-3.5.1.js', help='jQueryのパス指定(default:CDN Path)')
parser.add_argument('-R', '--rwdpath', required=False, default='js/jquery.rwdImageMaps.js', help='jQuery RWD Image Maps のパス指定(default:js/jquery.rwdImageMaps.js)')
parser.add_argument('-C', '--csspath', required=False, default='css/style.css', help='CSS のパス指定(default:css/style.css)')
return parser.parse_args()
if __name__ == '__main__':
args = getArguments()
args_flag = False
if checkArguments(args.width) != False and checkArguments(args.height) != False:
args_flag = True
if args_flag != False:
convertMain(args)
else:
exit()相変わらず殴り書きコードですがほんと許してください:D
使い方
こんな感じの構成になるように準備します。↓

①作成したPowerPointの全スライドを以下手順でPNG形式でエクスポート
「ファイル」>「名前を付けて保存」>「PNG」ですべてのスライドを保存
②エクスポートしたPNGをimageフォルダに格納
③PptxToHtml.pyと同レベルにパワポファイルを配置
④下記コマンドで実行
py PptxToHtml.pyデフォルトではimageフォルダ内のPNGファイルの大きさをベースとしてイメージマップを生成します。
実行オプションを指定することも可能です:)
-W --width クリッカブルマップ対象の画像の幅 (default:image内のpngサイズ)
-H --height クリッカブルマップ対象の画像の高さ (default:image内のpngサイズ)
-J --jqpath jQueryのパス指定 (default:CDN Path)
-R --rwdpath jQuery RWD Image Maps のパス指定 (default:js/jquery.rwdImageMaps.js)
-C --csspath CSS のパス指定 (default:css/style.css)そのままhtmlファイルを確認できます。
実行結果
実行するとこんな感じです↓
イメージマップになってますね!
今後の課題
ということで無事にパワポからイメージマップが作成できましたが、下記のような課題も見つかりました。
- クリック領域は矩形に限定されてしまう
- 背景画像も限定される
- 使い勝手が微妙
うーん…やはり実用化するにはいまひとつって感じですね:(
改善の余地ありまくりです。
勉強にはなったのでまあ良しとします!
おわりに
いかがでしたでしょうか!
PythonでパワポからHTMLを生成というすでにありそうな試みでしたが、何か発見があれば幸いです。
それにしてもPythonはいろいろなライブラリを簡単に試せて面白いですね:)
気が向いたらもう少し有効な使い方ができるように検討してみたいと思ます!
それでは、また:D


コメント